


In the prelude post we recorded that we were standing at a fork in the compositional verification design, and we left three questions unresolved. Each has now been pinned. The shape of the glue predicate is fixed by two definitions, state_join and state_refines. The derivation limit of the fair_leader assumption has been positioned explicitly within the Heard-Of model tradition as a deterministic abstraction. The inconsistency measure has been concretized as a count of mismatched chain pairs across domains, which lands automatically on a well-founded order over the natural numbers. This post is a compositional verification design-confirmation report written immediately before the .thy files go in. Stating the irreversibility of the decisions is the real function of this writing. The fork is now closed.
What It Means to Pin a Decision
Design-stage writing splits into two kinds. Posts that open questions and posts that pin answers. If the prelude was the former, this post is the latter. The difference between the two lies in how much the writing constrains the work that follows.
A question-opening post writes “this path is possible, that path is also possible”. It preserves degrees of freedom and catalogs possibilities. A pinning post writes “this path it is, the others are closed”. The latter deliberately reduces the degrees of freedom. There is a cost to that. Once a decision is pinned, it casts shadows on every branch of subsequent work.
So a design-confirmation post must not become a pretty sealing ceremony. It needs to record why a decision was pinned, what other decisions were closed by it, and what the cost of that closure is, all in the same place. That way, when subsequent work hits a wall, it is clear where one can step back to. The irreversibility of a decision and the preservation of its surrounding context are not in conflict. Marking the closed paths happens at the same moment the decision is made.
This post handles three decisions and two risk locations. The decisions concern the abstraction level of the composition, the form of the glue predicate, and the shape of the inconsistency measure. The risk locations are two places under those decisions where the proof could stall. Pinning the decisions and the risk locations in the same post is, we believe, a form of academic honesty.
From Open Questions to Pinned Decisions
At the end of the prelude post, three unresolved points were left open. The judgment was that the most fragile spots in the composition design should be written down in advance, as a form of honesty. A month later, the time has come to record what answers we placed in those three slots.
First, the precise form of the glue predicate
The prelude considered deferring the form of the predicate until an external sanity check. That strategy has been retired. Making the form of a code definition depend on an external response carries the risk of informal-formal mismatch, and that risk turned out to be decisive.
Behind this decision is something we learned in the previous cycle. AFP reviewers look very precisely at where and how the abstract’s claims correspond to the substance of the code. If the abstract emphasizes “a glue predicate connecting Merkle-authenticated state with cross-domain invariant preservation” and the body of the definition is left as a placeholder at submission time, the reviewer flags the mismatch immediately. “Is this the glue the writing was talking about?” becomes the first question. We came out of the previous cycle understanding that the precise correspondence between natural-language claims and formal expressions is tied directly to the credibility of the verification itself.
Instead, we will fix two definitions at AFP submission time. state_join expresses the relation by which two partial state views from different domains combine into a compatible joined view. state_refines expresses one view as a blinding refinement of another. The latter lifts Canton’s need-to-know model up through the blinding_of relation.
What about external feedback if it arrives later? It can be incorporated as a v2 incremental update after submission. AFP follows a monotone update principle, so an entry can be revised if a more natural definition is later proposed. The point of the decision is that the AFP submission itself will not depend on an external response. On the surface, the principle is academic robustness over working time; underneath sits a deeper meta-principle: do not pin external dependencies into code definitions.
Second, the derivation limit of fair_leader from the BFT structure
Here, the more honest answer was that full derivation is not possible. VRF-based leader election is intrinsically probabilistic, and to prove a deterministic theorem we must, somewhere, abstract a probabilistic guarantee into a deterministic sufficient condition.
The academic location of this abstraction is clear. Charron-Bost and Schiper’s Heard-Of model[1] has shaped roughly six decades of methodological tradition in the verification of distributed systems. The model converts the probabilistic nature of message delivery into a deterministic abstraction: the set of messages a node hears in each round. Theorems verified under that abstraction are then justified, by separate analysis, to also hold in the original probabilistic model. This two-stage verification is the standard structure of formal verification in distributed systems.
Wanner et al.[2] verified a log-replication protocol in a BFT setting using the same tool and the same abstraction; this is a direct precedent for our work. They proved safety and liveness together under the Heard-Of deterministic abstraction and explained the validity of the result in terms of its relation to the original probabilistic model. Our work sits inside the same methodological tradition.
The meaning of this positioning unpacks as follows. We do not claim that fair_leader is fully derived from the BFT structure. That would be false. What we do claim is that fair_leader is justifiable within the verified methodological abstraction of distributed-systems verification. And we explicitly catalog the limits of that abstraction. How exactly this positioning enters the scope statement is the most delicate part of writing the academic paper. State it too strongly, and one is accused of hiding the abstraction; state it too weakly, and one weakens the meaning of the result by one’s own hand. The narrow corridor between those two has to be hit precisely.
Third, the well-founded decrease of the inconsistency measure
This was the most precarious slot. In the prelude post we wrote, explicitly, that “if a release action propagates first to some domains, the count of inconsistent pairs may temporarily increase in intermediate states”. There were two ways to close that worry.
Path A would weaken the conclusion to eventuality. “At some point, the system reaches valid_state.” This form does not require strict decrease, so any branch of the case analysis can dispatch. The cost is that the strength of the result drops one step below guarded bounded convergence.
Path B adjusts the definition of the measure so that strict decrease is required only at the atomic unit. That is: “a sync operation is treated as an atomic unit, and within that unit inconsistency_pairs strictly decreases”. Partial sync states applied to only some domains are excluded from the model’s state space. Atomicity is then explicitly cataloged as a Class B assumption, to be discharged progressively in subsequent verification properties.
We chose Path B. The grounds for the decision split into two strands.
First, preserving the strength of the result determines the breadth of the academic contribution. Eventuality is weaker than bounded convergence, and a weaker result invites weaker citations. In the self-stabilization literature[5], the body of results accumulated since Dolev is largely in the bounded form. A result that stops at eventuality is hard to enroll into that accumulation. When to concede strength is one of the central variables of academic strategy.
Second, the atomicity assumption is one we can discharge in a subsequent property. The sync operation we abstract as atomic in the present composition step will be progressively unwound in later properties as preemptive lock correctness and cross-chain finality. That is, the introduction of the atomicity assumption does not weaken the final guarantees of the system. It merely delegates the proof obligation to a subsequent property. This delegation is the essence of a systematic verification program. There is no composition that releases all assumptions at once. The design of a verification program lives precisely in the question of which assumption is replaced by which other assumption at which stage.
This decision lets us carry the conclusion of the composition theorem all the way to guarded bounded convergence. The fact that the statement of that theorem drops the valid_state initial-state hypothesis is the decisive difference from the previous cycle’s combined_safety_liveness theorem.
With these three decisions, the design fork is closed. What remains is to pin them into .thy.
The 4-Locale Architecture
The pinned composition structure consists of four new locales and three new .thy files.
Composition.thy contains three domain-independent locales. guarded_invariant abstracts a system in which an invariant is preserved under a guard predicate. eventual_discharger abstracts a schedule in which guard-releasing events arrive within a finite window. safety_liveness_composition sits on top of the two sublocales and completes the composition by introducing the realize predicate. The words priority, leader, epoch, blockchain, and Byzantine do not appear in this file. This is a structural device for guaranteeing the breadth of the academic contribution.
Merkle_Composition.thy contains the fourth locale, authenticated_cross_domain. This file imports the Merkle_Interface locale from Lochbihler and Marić’s ADS_Functor AFP entry[3] and composes safety_liveness_composition on top of it. Merkle_Interface is a locale that fixes a hash function h, a blinding relation bo, and a partial merge operation m; its central theorem is the authenticity guarantee that “two authenticated data sharing the same hash must be merge-compatible”.
Integrated_Instance.thy instantiates the three locales above with Oraclizer’s actual semantics. oss_safety maps OSS’s BVC Phase 2 verification step to guarded_invariant; dquencer_liveness maps D-quencer’s fair leader scheduling to eventual_discharger; oss_composed instantiates the composition of the two; and oss_authenticated instantiates the combination with ADS_Functor.
Domain-independent locales are reusable in distributed databases, sharded blockchains, and ZK proof systems. The Canton-integrated locale and Oraclizer instances stay specific to this work.
dquencer_liveness ⊢ eventual_discharger
oss_composed ⊢ safety_liveness_composition
oss_authenticated ⊢ authenticated_cross_domain
The two domain-independent locales are reusable in distributed databases, sharded blockchains, and ZK proof systems. The Canton-integrated locale and Oraclizer instances stay specific to this work.
Figure 1: 4-Locale Composition Architecture
Why a 3+1 split
The 3+1 split in the four-locale structure above is not accidental. Without an answer pinned for “why this separation, and not another?”, we would have nothing to say if a reviewer proposed an alternative.
Three separation principles are at work.
First, vertical separation between the safety side and the liveness side. guarded_invariant handles only “the invariant is preserved under the guard”; eventual_discharger handles only “guard-releasing events arrive in finite time”. The two locales share no assumptions. This is the cleanest form of assume-guarantee composition. Bundling both sides into a single locale would mix assumptions and obscure which assumption is whose responsibility. Since Abadi and Lamport[4]’s composition specification work, the dominant pattern in distributed-systems composition has prioritized clean separation of responsibility.
Second, vertical separation between the composition layer and the authenticity layer. safety_liveness_composition handles composition; authenticated_cross_domain places authenticity on top. Bundling both into one file destroys the domain-independence of the composition. The structure where Composition.thy imports only Main, and Merkle_Composition.thy additionally imports ADS_Functor.Merkle_Interface, lets domains with different authenticity structures, like distributed-database replica convergence or Kubernetes controller reconciliation, import only the Composition.thy portion for their own purposes. Domains that need authenticity also import Merkle_Composition.thy.
Third, vertical separation between abstract framework and concrete instance. Two of the three new files are domain-independent, and only one (Integrated_Instance.thy) carries Oraclizer’s semantics. This separation is tied directly to the measurability of the academic contribution. If a researcher in another field imports Composition.thy for their own domain, that act becomes after-the-fact evidence that the abstraction was correct. Mixing instances with framework would make that measurement impossible.
Whether this 3+1 structure can become a baseline form for compositional verification will be answered by future imports from other domains. The scope of the present work goes only as far as showing, through one Oraclizer instance, that the framework actually operates.
Enforcing domain independence at the word level
The breadth of an academic contribution comes not from intended abstraction but from abstraction enforced at the word level. The fact that priority, leader, and Byzantine do not appear in Composition.thy is not accidental; it is an explicit design constraint.
That constraint is pinned in a form that is grep-able at review time. When an AFP reviewer asks “is this locale really domain-independent?”, word-level enforcement is itself the answer. If even a single occurrence of priority were found in Composition.thy, that location would immediately become a weakness in the abstraction decision. So the word-level check is performed by automated grep right after writing.
Similarly, whether Merkle_Composition.thy actually uses the theorems from ADS_Functor is also checked by grep. If it imports but does not use them, there is no answer to “why import?”. “A general nod to a colleague using the same tool” cannot be the purpose of an import. The central theorem of merkle_interface (merge respects hashes) must be invoked as an explicit step inside the proof bodies of our two main theorems (authenticated_preservation_soundness and blinded_view_preserves_invariant).
The accumulation of these checks is what informal-formal match looks like in practice. We have pinned this as a self-check list of twelve items to run immediately after writing.
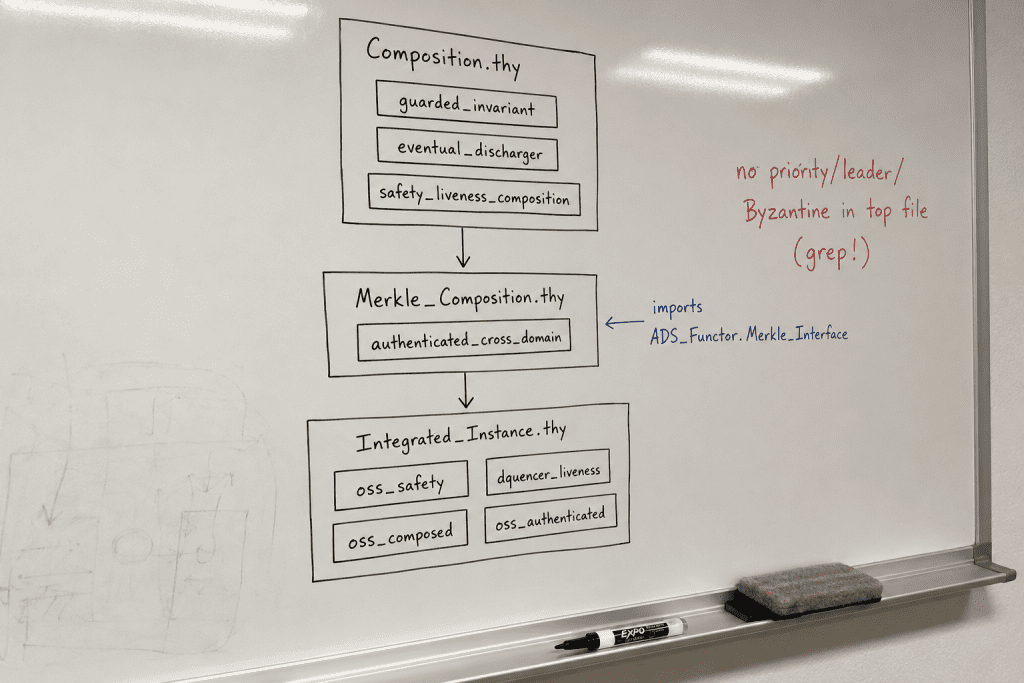
The composition structure transferred onto a meeting room whiteboard, with the domain-independence enforcement items noted in red on the side. The red marks list words to grep for after writing.
Concretizing the Glue Predicate
Read out in natural language, state_join and state_refines mean the following.
state_join sa sb sab expresses “two partial state views sa and sb combine into a consistent joined view sab“. Concretely, for an asset aid on a chain c, the regulatory state known to sa on c and the regulatory state known to sb on c must be compatible, and on the union of the two chain sets, sab must preserve exactly whichever side knew the value. This lifts Merkle_Interface‘s merge operation to the state level. If two authenticated data are merge-compatible, then the two cross-domain state views extracted from them must also be join-compatible.
state_refines sa sb expresses “sa is a blinding refinement of sb“. For every (chain, asset) pair known to sa, sb also knows the same information and the values agree. That is, sa is a partial view of sb. This corresponds exactly, in Canton’s need-to-know privacy model, to the guarantee that the view seen by a less-privileged participant is a consistent subset of the view seen by a more-privileged one.
Both predicates lift Merkle_Interface‘s merge and blinding_of operations to the cross-domain state level. Merge lifts to state_join; blinding lifts to state_refines.
sab covers the union of known chains.
sa knows a chain, the value matches sb exactly. Other chains are hidden under blinding.
Both predicates lift Merkle_Interface‘s merge and blinding_of operations to the cross-domain state level.
Figure 2: Glue Predicate Semantics
How the two definitions lift Merkle_Interface‘s merge and blinding_of
The correctness of this lifting is the mathematical heart of the composition design. It is easy to write in natural language that the operations “are lifted to the state level”; what determines the value of the verification asset is which theorems are preserved at the code level by that lifting.
The central guarantee of merge is “two data sharing the same hash are merge-compatible”. Lifted to the state level, this becomes “two compatible partial views of the same asset are join-compatible”. Equality of hash lifts to equality of asset identifier together with compatibility of regulatory state. If two asset identifiers differ, joining is meaningless; if they agree, the regulatory states of the two views must be compatible. That compatibility condition is the state-level version of hash equality.
The central guarantee of blinding_of is “a partial view is consistent with the full view”. Lifted to the state level, this becomes “a refined view agrees with the full view on its known chains”. The partiality of the data structure lifts to partiality of state information. Just as in Canton’s need-to-know model the view of a less-privileged participant is a blinded result, our state_refines lifts that model to the cross-domain state level.
These two liftings are not arbitrary abstractions; they are natural extensions of the guarantees provided by Merkle_Interface. That is why Merkle_Interface‘s theorems are actually invoked inside the proof bodies of the two definitions. The proof of authenticated_preservation_soundness uses merge respects hashes directly to derive “merge-compatible → join-compatible”. The proof of blinded_view_preserves_invariant uses the hash-preservation property of blinding to derive “blinded view → refined state”.
Whether these invocations appear as explicit steps determines the academic significance of the ADS_Functor import. If the invocations are buried in automated simplification, there is no way to answer the reviewer’s question “is this import really necessary?”. After writing, we grep for the locations of merkle_interface theorem invocations.
Why these are not ad hoc definitions
There are two reasons why state_join and state_refines are not definitions tailored to our domain. First, the two definitions are semantically compatible with the signature fixed by Merkle_Interface. This guarantees the academic legitimacy of the import. Second, the two definitions apply naturally to domains beyond Canton. In replica synchronization for distributed databases, state_join becomes the relation under which two replicas’ partial states combine into a consistent merged state. In ZK proof systems, state_refines expresses that the public state seen by the verifier is a blinded refinement of the prover’s full witness state.
Without making this generality explicit in prose, the domain-independence of the definitions does not show just from the code. So in root.tex we pin the reuse scenarios for distributed databases, sharded blockchains, and ZK proof systems as explicit prose. The abstractness of the code and the universality of the prose together form the academic asset.
The Inconsistency Measure as the Critical Path
The critical path for carrying the conclusion of the composition theorem to the strength of guarded bounded convergence lives in Integrated_Instance.thy.
definition inconsistency_pairs :: "global_state ⇒ nat" where
"inconsistency_pairs gs =
card {(c1, c2, aid).
c1 ∈ connected_chains gs aid
∧ c2 ∈ connected_chains gs aid
∧ c1 < c2
∧ get_reg_state gs c1 aid ≠ get_reg_state gs c2 aid}"
If this count is zero, the system is consistent; if non-zero, the regulatory state of some asset disagrees across domains. Proving that the measure is strictly decreasing on a well-founded order implies that, starting from any initial state, the measure reaches zero in finite time. That is, convergence.
The central lemma takes this form.
lemma sync_reduces_inconsistency:
assumes "¬ consistent_state gs"
and "conflict_resolving_sync gs src act aid = Some gs'"
shows "inconsistency_pairs gs' < inconsistency_pairs gs"
The slot we worried about most in the prelude post is exactly this lemma. Does every synchronization strictly reduce inconsistency? Doesn’t a release-class action propagating first to some domains temporarily increase the count of inconsistent pairs in intermediate states?
The answer lies in the atomicity abstraction of conflict_resolving_sync. In the present composition step, we abstract a single sync operation as an atomic unit. That is, “the intermediate state where sync has been applied to only some domains” is not in the model’s state space. This atomicity is cataloged as a Class B assumption and will be progressively unwound in subsequent verification properties via lock correctness and cross-chain finality proofs. At this stage, we prove strict decrease only at the granularity of atomic sync.
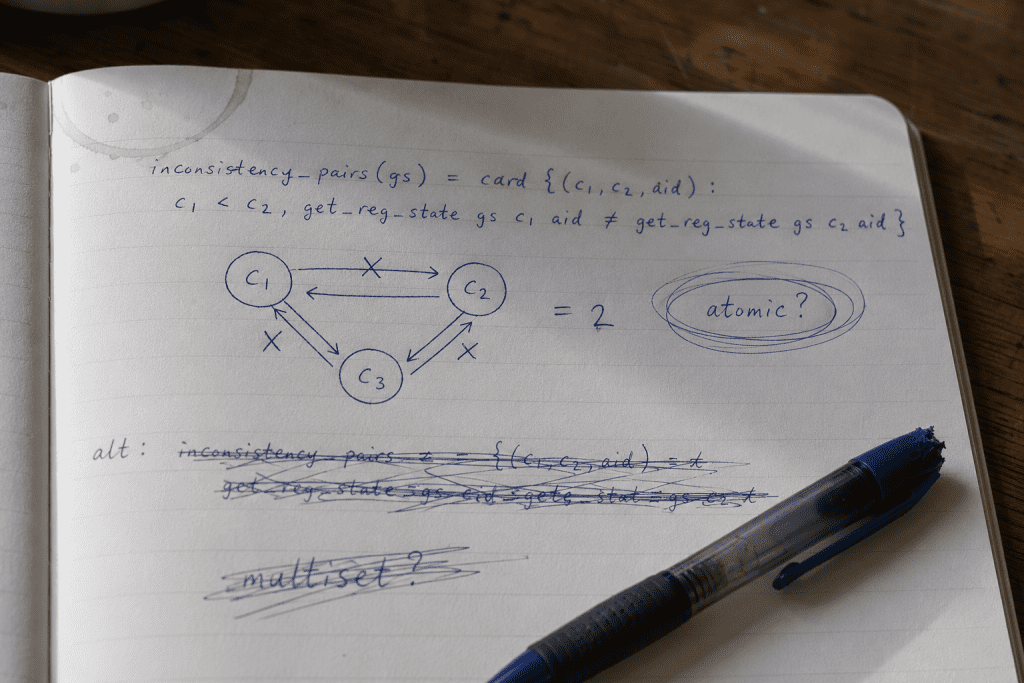
A handwritten note where the inconsistency_pairs definition was first pinned down, with the counter-example scenario sketched out in pen.
Why a natural-number count
Defining the inconsistency measure as a natural-number count is also a deliberate decision. More general measures were available.
A multiset order can be used to weight the degree of mismatch per (chain, asset) pair. A lexicographic order can be used to resolve mismatches in higher-priority assets first. Both forms are well-known to be well-founded in the distributed-systems verification literature.
Even so, we chose the natural-number count for two reasons: simplicity of proof and universality of abstraction.
Strict less-than on the naturals is the most basic well-founded order Isabelle/HOL provides. Proving strict decrease automatically yields finite-time convergence. The pattern of induction on the measure is in the standard library directly. Moving to multiset or lexicographic orders turns well-foundedness itself into additional work, and that work pulls away from the subject of the composition theorem. The main message of our result is “composition is possible”, not “we handle complex measures well”.
The natural-number count also has higher reusability. When researchers in other domains apply the guarded_invariant + eventual_discharger composition to their setting, the natural-number count measure is the form most frequently encountered. Multiset or lexicographic orders increase re-implementation cost. The measure at the abstraction layer should be the most basic form, leaving open the path to specialization in more elaborate forms later.
The cost of this decision is precision of the measure. Since all inconsistent pairs are weighted equally, information like asset importance or distance between chains is not reflected in the measure. But that precision is not needed at the composition step. The fact that convergence happens is the central result; how fast convergence happens belongs to subsequent quantitative analysis.
What well-foundedness gives for free
Two things follow automatically for the composition theorem from the fact that strict less-than on the naturals is well-founded.
First, finite-time convergence. A strictly decreasing sequence of naturals reaches zero in finite time. This is the definition of well-foundedness itself. No additional work needed.
Second, explicit bounds. Given an initial measure value m₀, the number of steps to convergence is at most m₀. The composition theorem can therefore carry an explicit bound: “convergence within m₀ steps”. That is one step stronger than eventuality.
These two facts are the mathematical foundation that lets the conclusion of the composition theorem reach guarded bounded convergence. Without a well-founded measure, bounded convergence cannot be proven.
That said, a risk remains even on this foundation. sync_reduces_inconsistency must guarantee strict decrease in every case. If even one branch is non-strict or increases, well-foundedness on the naturals alone is no longer enough. Which case Isabelle returns a counter-example for is one of the key variables of the .thy-writing stage.
Position in the self-stabilization literature
Where in the distributed-systems literature this result sits is also part of the design decisions.
Guarded bounded convergence connects directly to the self-stabilization literature, introduced by Dijkstra in 1974 and synthesized in Dolev’s 2000 book[5]. The classical form of self-stabilization is “starting from any initial state, reach a legitimate state in finite time”, which has exactly the same shape as our conclusion.
However, our result is not pure self-stabilization but a variant called assisted self-stabilization. External regulatory actions intervene in the system and dynamically determine the definition of the legitimate state. That is, while the system self-stabilizes, which state it should stabilize to can itself shift under external input. This variant is well-known in the self-stabilization literature, but mechanized proofs in a blockchain setting, as far as we know, are rare.
Exactly where this positioning lands is decided in the related work section of the academic paper. State it too strongly as “a new result” and one is criticized for ignoring the continuity of the self-stabilization tradition. State it too weakly as “an instance of an existing result” and the blockchain-specific portion of our result disappears. Our location will be pinned precisely as “a mechanized result that applies the verification methodology of the self-stabilization tradition to blockchain regulatory consensus”.
Where We Stand at the Boundary of Risk
The real meaning of pinning a design is not “all risk has disappeared”. It is that we have stated where the risk has been narrowed to. The risks of the compositional verification design we have pinned concentrate at two places.
The first risk is the type lifting of the realize predicate. The realize in safety_liveness_composition is type-polymorphic. At the abstraction stage, it has the form 'event ⇒ 's ⇒ 'op option, and at the instantiation stage it must map onto D-quencer’s select_highest over priority_system. If that mapping does not arise naturally, the abstraction laid down in Composition.thy will collide at the instance level.
The second risk is the strict-decrease proof of the inconsistency measure discussed above. If the case analysis stalls in any single branch, well-foundedness on the naturals does not by itself rescue the conclusion.
Outside of these two locations, the rest of the work can be handled almost entirely with material from the two completed properties. Instances of guarded_invariant can reuse the actual usage patterns of the state_preservation locale. Instances of eventual_discharger nearly match the fair_leader_system instantiation pattern. authenticated_cross_domain is a new locale, but ADS_Functor’s signatures are clearly published, so type-compatibility risk is low.
Working with risk narrowed to two places is completely different labor from working without knowing where the risk lies. Drawing the map of risks at the design-confirmation stage is the essence of preserving context across the fork.
The 7-File Layout and Entry Strategy
The pinned file structure is as follows.
Compositional_State_Assurance/ ├── ROOT ├── document/ │ ├── root.tex │ └── abstract.tex ├── State_Preservation.thy # existing Property 1 framework (relocated) ├── Regulatory_Instance.thy # existing Property 1 instance (relocated) ├── Priority_Resolution.thy # existing Property 2 framework (relocated) ├── DQuencer_Instance.thy # existing Property 2 instance (relocated) ├── Composition.thy # new: domain-independent 3-locale composition ├── Merkle_Composition.thy # new: ADS_Functor integration └── Integrated_Instance.thy # new: Oraclizer instantiation
The four existing files will be relocated into the new entry. AFP practice permits coexistence of related entries from the same author, and splitting them into two entries with clearly different scopes is also clearer for reviewers. External imports are limited to two: Main and ADS_Functor.Merkle_Interface. Minimizing dependencies reduces review burden and improves build stability.
This entry is not a single-axis output but an integrated package combining safety + liveness + composition + Canton integration. The scenario of bundling it with the first property’s entry as a monotone update was considered, but the difference in scope is large enough, and the new entry’s thematic cohesion is stronger.
The academic meaning of relocating four files
The decision to relocate the four files of the existing Cross_Domain_State_Preservation entry into the new entry might appear, on the surface, like a copy-and-paste. The academic meaning is otherwise.
The existing entry is a single-axis output covering safety only. The new entry packages safety + liveness + composition + Canton integration together. The two entries have different topics and different units of contribution. Including the four existing files in the new entry is a way of making explicit that the composition work happens on top of those four files. It guarantees that a reviewer can build and verify the new entry as a self-contained unit.
The alternative was to import the existing entry inside the new one. That form avoids code duplication but carries three costs. First, changes in the existing entry affect the new entry’s build. Second, build-consistency issues can arise from a verification-time skew between the two entries. Third, reviewers have to verify both entries together.
Relocation, following the self-contained principle, sidesteps all three costs. AFP practice permits separate entries with thematic cohesion from the same author, and several active AFP authors maintain multiple separate entries on related topics. We work within that practice.
What This Design Does Not Promise
Another way to demonstrate the soundness of a design is to state explicitly what it does not promise. The present composition design does not prove the following.
Composition over a partial-synchrony network model. Composition in environments with message delay, retransmission, and reordering is not handled under the present synchronous-model assumption. The gap between synchronous and partial-synchrony models is well-known in the distributed-systems verification literature, and transferring results between the two requires separate justification. The present composition first secures the result under the synchronous model; extension to partial synchrony is left to a subsequent verification property.
Starvation freedom in an open system. Starvation freedom in an environment of continuously arriving requests is not handled under the present closed-system assumption. It is no accident that most verified results in the Heard-Of model tradition assume closed systems. Extension to open systems requires deeper machinery from fairness theory, and is a long-term task.
Formal refinement between the model and the Rust implementation. What we verify is the model, not the code. Code-level refinement is the territory of Rust verification tooling, like Creusot and Kani, to be progressively introduced later, and is not an output of the present composition step.
Our methodological position on the model-implementation gap consists of three independent lines of defense. First, model-level verification has independent academic value in the distributed-systems literature of the Heard-Of model tradition. Second, the FORMAL_MODEL_MAPPING.md document in the GitHub repository publicly tracks the correspondence between model and implementation modules. Third, subsequent verification properties progressively discharge the abstraction assumptions cataloged at this stage. The three lines of defense together form the legitimacy of a systematic verification program.
Probabilistic analysis of VRF-based leader election. fair_leader is a deterministic abstraction. This abstraction lives within the verified methodology of the Heard-Of model, and the reduction to a probabilistic model is a separate effort in the distributed-systems field.
Authenticity guarantees inside Canton. The correctness of the hash function and blinding relation fixed by Merkle_Interface is handled by ADS_Functor as part of Canton’s own FV. We import that and compose on top of cross-domain paths. Internal Canton verification and cross-domain compositional verification are different responsibility areas; this separation makes the academic location of the composition work cleaner.
Each item maps either to an explicit work item of a subsequent property or to long-term future work. That the composition is not complete is not a weakness; that the boundary is clearly drawn is the strength of the design.
sync_reduces_inconsistency to hold strictly in every case branch.eventual_discharger.eventual_discharger‘s window to be defined in discrete rounds.Figure 3: Class B Assumption Catalog
The cumulative structure of compositional verification
The five things this design does not promise above are not a simple list of limitations. Each item defines the work area of a subsequent verification property. That is, the present composition work is not a standalone output but one stage of a systematic verification program.
The atomic sync assumption is discharged in the subsequent preemptive lock correctness property. The cross-chain message integrity area is treated by a separate property, forming a distinct responsibility area from the present composition step’s atomicity assumption. The probabilistic analysis of VRF is a longer-term separate task addressing the general reduction between Heard-Of model and probabilistic model.
This cumulative structure is the essence of a systematic verification program. There is no verification that releases all assumptions at once. Each stage must specify which assumption it introduces and which it discharges, and the flow of assumptions must remain coherent. The Class B assumption catalog at the present composition stage is one cross-section of that flow.
Next: From Skeleton to Verified Theorems
From the time this post is published until the next post, the work proceeds as follows.
The Compositional_State_Assurance/ folder is created and the four existing .thy files are relocated. The ROOT file and document/root.tex are written. Then Composition.thy is written in full: locale definitions, main theorems, proof bodies. After completion, isabelle build verifies zero sorry. On pass, the next file is taken up: Merkle_Composition.thy, then Integrated_Instance.thy.
Each file is treated as an independent verification unit. Isabelle automatically loads imported theories as a heap image, so the focus stays on one currently verified file. Sequential progression, where one file must pass with zero sorry before the next, secures verification stability.
The central commitment of this workflow is that “the cycle of edit and rebuild is normal operation”. When the build reports a sorry or a type error, that report drives the next edit → rebuild. Until a file passes. The condition for passing is clear: zero sorry. But that alone does not complete the entry. Twelve informal-formal match check items must also be satisfied. Whether the body of each definition corresponds precisely to the abstract’s natural-language claim, whether ADS_Functor‘s theorems are actually invoked in proof bodies, whether subsequent property numbers are not exposed in externally-public text, whether vague phrases (“obvious”, “trivially”, “clearly”, “straightforward”) are absent from the academic entry.
Whatever counter-examples and type-mismatch messages Isabelle returns to us are material for the next post. That post will be a debugging retrospective, while the present post is the design report just before entering the proof. Between the two posts, what happens is the build-pass of the .thy files, and the design defects discovered, along with their corrections, become the body of the next post.
To the Reader
In the prelude post we wrote that “if safety_liveness_composition instantiates naturally for replica convergence in distributed databases or for reconciliation in Kubernetes controllers, then this work becomes not a blockchain-specific output but a verification methodology for distributed systems in general”. The present post records how that promise is pinned at the code level, through the four-locale structure.
That said, actual instantiation in those domains is outside the scope of this entry. The present composition design carries only one Oraclizer instance. Other-domain instantiations are subsequent work, and the appropriateness of the abstraction level will be verified after the fact by their results. If a researcher in another field imports guarded_invariant or eventual_discharger into their domain and derives a meaningful theorem, that becomes evidence the abstraction decision was correct. If no such import occurs, the after-the-fact assessment becomes over-abstraction.
This after-the-fact verification is outside our control. We can only write the locales in a form that lowers the entry barrier of abstraction, and explicitly state the reuse scenarios in prose. The next move belongs to other researchers in distributed systems.
One final piece of meta-reflection on the irreversibility of decisions. The decisions in this post become solidified in the form of code the moment we begin writing .thy files. Decisions written down in design-stage prose can be revised; decisions in code that have passed a build and been submitted as an entry can be revised only by incremental update. So the writing just before .thy carries a different weight. The decisions written here become material to revisit in the next post.
If the retrospective concludes that the decisions were correct, the present post becomes prophecy. If it concludes they were wrong, the present post becomes record. Either way, the place of this post does not disappear. Both prophecy and record contribute to the integrity of academic work. A research program whose published writings always conclude that decisions were correct is not, in any honest sense, a verification program.
References
[1] Charron-Bost, B., & Schiper, A. (2009). The Heard-Of Model: Computing in Distributed Systems with Benign Faults. Distributed Computing, 22(1), 49-71. Link
[2] Wanner, A., Goncalves, M., & Yin, K. (2020). A Formally Verified Protocol for Log Replication with Byzantine Fault Tolerance. IEEE SRDS 2020. Link
[3] Lochbihler, A., & Marić, O. (2020). Authenticated Data Structures as Functors in Isabelle/HOL. FMBC 2020, OASIcs vol. 84. Archive of Formal Proofs entry: ADS_Functor.
[4] Abadi, M., & Lamport, L. (1995). Conjoining Specifications. ACM Transactions on Programming Languages and Systems, 17(3), 507-534. Link
[5] Dolev, S. (2000). Self-Stabilization. MIT Press. Link
[6] Kim, J. (2026). Safety and Liveness of Cross-Domain State Preservation under Byzantine Faults: A Mechanized Proof in Isabelle/HOL. arXiv:2604.03844. Link
Learn More
Bridging Safety and Liveness: A Prelude to Compositional Verification
Byzantine Fault Liveness, Discharged: What Properties 1 and 2 Together Guarantee



