


TL;DR
- State oracles require a fundamentally different proof architecture than data oracles. They must prove the correctness of continuous state flows, not discrete value verification.
- The GKR protocol provides the computational foundation that makes state oracles possible. By eliminating intermediate commitments, it reduces proof generation computation by 10-15× compared to traditional approaches.
- Oraclizer applies GKR to OSS for high-frequency state synchronization verification, achieving over 99% circuit constraint reduction. D-quencer consensus operates on BLS multisig, which is sufficient for its epoch-level frequency.
- The fflonk proving system offers favorable characteristics for continuous state synchronization, with lower verification overhead and universal setup compatibility within the CDK framework.
Part 1: The Nature of Proofs State Oracles Demand
The Fundamental Difference Between Data and State Oracles
When designing blockchain oracle systems, we often frame the problem simply as “bringing external data on-chain.” However, this definition applies only to data oracles—a limited perspective.
Traditional oracles like Chainlink or Pyth deliver discrete values at specific points in time—prices, weather data, sports results. These values are essentially snapshots. The only proposition to verify is “was this value accurate at a particular moment?”
State oracles must solve an entirely different problem. RWA states change continuously, and these changes are causally connected. Bond interest payments, collateral ratio fluctuations, regulatory status transitions—all form a coherent state flow.
“Traditional proof systems were designed for a world of discrete verification. State synchronization demands proofs for continuous computational flows—a fundamentally different mathematical structure.”
The implications for proof system design are profound. Data oracles verify N independent values. State oracles must prove that N interconnected state transitions are all valid.
The Computational Burden of Intermediate Commitments
Traditional SNARK systems—Groth16, PLONK, even STARKs—generate commitments for every intermediate step of computation. This is the standard approach for ensuring proof soundness.
The problem is computational overhead. Consider proving a single Poseidon hash operation. Poseidon takes an input through multiple rounds of matrix multiplication and S-box operations to produce an output. In traditional approaches, each round requires commitments to intermediate values.
Proof Requirements Comparison
DATA ORACLE
Single Value Verification
- One aggregated value
- Minutes to hours frequency
- Simple signature check
STATE ORACLE
Continuous State Flow Verification
- N state transitions per batch
- Continuous / per block
- Batch computation proof
Key: Cost sensitivity is critical for state oracles due to continuous proof requirements
Figure 1: Data Oracle vs State Oracle Proof Requirements
Vitalik Buterin clearly articulated this problem in his October 2025 GKR tutorial:
“In the full Poseidon or Poseidon2 hash, you have a few rounds with M, then a few rounds with a simpler matrix that just has one diagonal, and then a few more rounds with M. Proving each layer naively would require hundreds of hash operations just to verify a single round.”
— Vitalik Buterin, “A GKR Tutorial”
For state oracles, this computational burden becomes critically amplified. If a single state synchronization event includes dozens of hash operations, and such events occur hundreds of times per second, intermediate commitment computation alone renders the system infeasible.
This is why we turned our attention to the GKR protocol.
Part 2: The GKR Protocol—Eliminating Intermediate Commitments
The Recursive Structure of the Sumcheck Protocol
The GKR (Goldwasser-Kalai-Rothblum) protocol was proposed as a theoretical construction in 2008, but practical implementations have only recently become feasible. Its core is the recursive application of the sumcheck protocol.
The basic idea of sumcheck is this: when you want to verify the sum of a multivariate polynomial, the verifier can probabilistically verify it through random challenges instead of directly computing every term.
Consider verifying the sum H:
$$H = \sum_{x_1 \in \{0,1\}} \sum_{x_2 \in \{0,1\}} \cdots \sum_{x_n \in \{0,1\}} f(x_1, x_2, \ldots, x_n)$$
To confirm the correctness of \(H\), the verifier asks the prover for a partial sum over the first variable \(x_1\):
$$g_1(X_1) = \sum_{x_2, \ldots, x_n \in \{0,1\}^{n-1}} f(X_1, x_2, \ldots, x_n)$$
The verifier checks whether \(g_1(0) + g_1(1) = H\), then selects a random value \(r_1\) to proceed to the next round. When this process recursively repeats for all variables, only polynomial evaluation at a single point needs to be verified at the end.
GKR applies this sumcheck to layered arithmetic circuits—computation flows upward from inputs through alternating addition and multiplication gates:
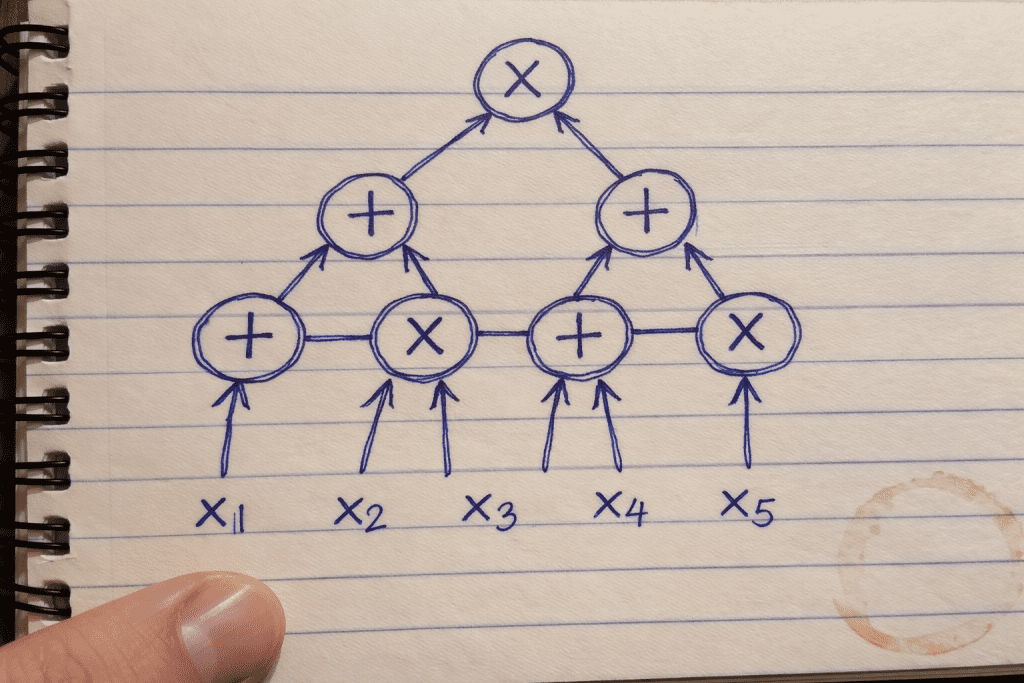
The verifier starts from the claimed output at the top and recursively verifies each layer downward using sumcheck, until reaching the inputs. This layered structure is precisely why intermediate commitments become unnecessary.
The key insight is:
There is no need to commit to intermediate layer values. The verifier can start from the final output and verify backwards to the input by recursively applying sumcheck.
The Natural Fit Between Poseidon Hash and GKR
The Poseidon hash structure demonstrates why GKR is ideal for state oracles.
Poseidon2 hash consists of the following structure:
- First 4 rounds: linear transformation using matrix M
- Middle 24 rounds: transformation using diagonal matrix (diag + J)
- Final 4 rounds: matrix M again
Each round applies a nonlinear operation \(x_i \rightarrow x_i^3\) followed by linear mixing. In traditional SNARKs, intermediate state commitments are required for each of the 32 rounds.
In GKR, this entire computation is represented as a single layered circuit. The verifier:
- Starts from the final hash output
- Verifies the correctness of the last round through sumcheck
- Recursively repeats this to reach the input
Commitments for all 32 intermediate rounds are completely eliminated.
According to Buterin’s benchmarks, this approach achieves theoretical efficiency improvements of 15× over STARKs, with real-world implementations showing approximately 10× gains. In isolated GKR implementations, regular laptops can prove 2 million Poseidon hashes per second, and approximately 50 consumer GPUs can prove the entire Ethereum L1 in real-time.
GKR and Zero-Knowledge: A Critical Distinction
It must be clearly understood that GKR itself does not provide zero-knowledge properties. GKR is purely a mechanism for computational efficiency—it verifies that a computation was performed correctly, but does not hide the inputs or intermediate values from the verifier.
In Oraclizer, when privacy is required, GKR is wrapped with a ZK-SNARK layer. The role of GKR is computational efficiency in proof generation; zero-knowledge properties are guaranteed by a separate layer. This separation of concerns allows us to apply GKR’s efficiency benefits while maintaining privacy guarantees where needed through the fflonk wrapping stage.
What This Means for State Oracles
Let us analyze concretely what this computational improvement means for state oracles.
The OSS (Oracle State Synchronizer) performs the following operations during state synchronization:
- Batch hash verification of state roots
- Batch processing of Merkle proofs
- Integrity verification of cross-chain messages
These operations occur at high frequency—dozens of times per minute—and follow a pattern where the same function is repeatedly applied to large amounts of data. This is exactly the domain where GKR excels.
The D-quencer, in contrast, performs consensus operations at epoch-level frequency:
- BLS signature aggregation and verification
- VRF-based leader selection
- State commitment generation during epoch transitions
Because D-quencer consensus occurs only once per epoch—a much lower frequency than OSS state synchronization—BLS multisig is sufficient for its security requirements. The computational overhead of intermediate commitments does not accumulate problematically at this frequency. GKR optimization is therefore concentrated on OSS, where the high-frequency nature of state synchronization makes intermediate commitment elimination critical.
Without GKR, hundreds of intermediate commitments would be required for each state synchronization event. To prove continuous state flows, this computational burden accumulates linearly over time. As a result, state oracles remain a concept that is theoretically possible but computationally infeasible.
With GKR applied to OSS, we can commit only to inputs and outputs, verifying the entire intermediate process through sumcheck. This is the critical inflection point that transforms state oracles into a feasible primitive.
Part 3: SNARK Selection—fflonk and State Synchronization
Characteristics of fflonk for Continuous State Flows
While GKR provides computational efficiency in verification, a SNARK system is still needed for final proof generation and on-chain verification. As noted, GKR does not provide zero-knowledge properties, nor does it have the succinct proof format required for on-chain verification.
In examining proof systems compatible with Polygon CDK, fflonk presents several characteristics favorable for state synchronization workloads:
| System | Trusted Setup | Proof Size | Verification Gas | Lookup Support | Key Characteristic |
|---|---|---|---|---|---|
| Groth16 | Circuit-specific | ~200 bytes | ~200K gas | Limited | Smallest proofs |
| PLONK (KZG) | Universal | ~500 bytes | ~300K gas | Full | Flexibility with custom gates |
| fflonk ★ | Universal | ~300 bytes | ~180K gas | Full | CDK Default |
| Halo2 | Trustless (IPA) | ~5-10 KB | ~500K gas | Full | No trusted setup |
| STARKs | Transparent | ~50-200 KB | ~1M+ gas | Full | Post-quantum secure |
Table: SNARK Systems Gas Cost and Feature Comparison
fflonk is a PLONK variant that reduces verification gas consumption by approximately 40% while maintaining the flexibility of Universal Trusted Setup. For state synchronization scenarios where proofs are generated frequently and in high volume, lower per-proof verification overhead compounds over time.
The universal setup characteristic is particularly relevant for state oracles. Unlike data oracles that verify fixed-format values, state synchronization involves diverse operations—hash verifications, signature aggregations, state transitions—that benefit from not requiring circuit-specific trusted setups.
Since Polygon CDK natively supports fflonk, this choice also aligns with our approach of focusing customization efforts on OSS rather than modifying the underlying CDK components. The zkProver and Executor remain unchanged; our innovations concentrate on the state synchronization layer.
The Proof Generation Pipeline
The integration of GKR and fflonk forms a hierarchical proof structure:
[OSS] → GKR → OSS State Root → [CDK] → fflonk → [zkVerify] → Batch Verify → [L1]
↑
(committed via CDK transaction)- OSS State Update: State synchronization operations execute in OSS
- GKR Proof Generation: OSS generates GKR proofs for internal verification (L3 layer)
- OSS State Root Commitment: Verified state root is committed to CDK via transaction
- CDK Block Proof: CDK zkProver generates fflonk proof for the block containing OSS commits
- zkVerify Submission: Only fflonk proofs are submitted to zkVerify for batch verification
The important point is that GKR reduces prover-side computation within OSS. GKR proofs remain at the L3 internal layer and are not submitted to zkVerify. Verifier-side gas consumption is addressed separately through zkVerify batch aggregation of CDK’s fflonk proofs.
Part 4: Batch Verification Through zkVerify
The Economics of Verification
On-chain verification of fflonk proofs consumes approximately 180,000 gas. If state synchronization occurs dozens of times per second, verification gas alone renders the system economically challenging.
zkVerify, developed by Horizen Labs, is a modular verification network that offloads zk proof verification from Ethereum mainnet to a dedicated verification layer. The core mechanism is batch aggregation:
Individual verification: \(N \times 180,000\) gas
Batch verification: \(180,000 + N \times 20,000\) gas
For N=100, individual verification requires 18,000,000 gas, while batch verification consumes only 2,180,000 gas—approximately 88% reduction.
However, this reduction in verification gas has been discussed extensively. What we should focus on is the computational reduction GKR brings on the proof generation side.
GKR Application in OSS
OSS performs large volumes of hash operations during state synchronization. Representative examples include:
- Path hashing during SMT (Sparse Merkle Tree) updates
- Integrity verification of cross-chain messages
- State root calculation
Assume batch processing of 100 state updates. If each update requires an average of 10 Poseidon hashes, 1,000 hash operations are needed in total. Based on theoretical circuit analysis, the two approaches compare as follows.
Traditional SNARK approach:
- Each hash: 32 rounds × intermediate commitments
- Total circuit constraints: ~32,000,000
- Proof generation time: tens of seconds
After GKR application:
- Intermediate commitments eliminated
- Total circuit constraints: ~320,000
- Proof generation time: hundreds of milliseconds
This difference determines the computational feasibility of continuous state synchronization.
Role Separation: OSS vs D-quencer
A natural question arises: why not apply GKR to D-quencer’s BLS signature aggregation as well?
The answer lies in frequency requirements. D-quencer consensus—BLS aggregation and VRF leader selection—occurs once per epoch. At this frequency, the computational overhead of traditional proof systems does not create a bottleneck. BLS multisig provides sufficient security guarantees without the complexity of GKR integration.
OSS state synchronization, however, operates at a fundamentally different timescale. State updates occur dozens of times per minute, and each requires proof generation. Without GKR’s elimination of intermediate commitments, proof generation time would exceed the interval between state updates—making continuous synchronization computationally infeasible.
This role separation follows the principle of applying optimization where it is necessary:
| Component | Proof System | Frequency | zkVerify Submission |
|---|---|---|---|
| D-quencer | BLS Multisig | Once per epoch | No |
| OSS | GKR | Per state update | No |
| CDK | fflonk | Per block (async) | Yes |
Part 5: The Three-Stage Proof Optimization Framework
Integrated Architecture
Integrating the technologies discussed, Oraclizer’s proof optimization consists of a three-stage framework:
Stage 1: Computation Verification (GKR)
- Application point: OSS
- Role: Eliminate intermediate commitments, reduce proof generation computation
- Effect: 99%+ circuit constraint reduction for high-frequency state synchronization
Note: D-quencer operates on BLS multisig for epoch-level consensus, which does not require GKR optimization.
Stage 2: Proof Generation (fflonk)
- Application point: CDK zkProver
- Role: ZK-SNARK proof generation for L3 blocks containing OSS State Root commits
- Effect: Zero-knowledge properties, CDK compatibility
Stage 3: Batch Verification (zkVerify)
- Application point: Ethereum mainnet ↔ zkVerify network
- Role: Batch aggregation verification of CDK fflonk proofs
- Effect: 88%+ verification gas reduction
OSS state update → GKR proof (L3 internal)
↓
OSS State Root
↓ (committed via CDK transaction)
CDK block → fflonk proof → zkVerify → Base L2CDK Integration Points
Oraclizer’s L3 infrastructure is built on Polygon CDK. GKR integration is performed without modifying CDK itself:
- CDK zkProver: Used without modification. Handles fflonk proof generation for L3 blocks
- CDK Executor: Used without modification. Handles transaction execution
- OSS: GKR circuit construction and sumcheck execution for state synchronization
- D-quencer: BLS multisig consensus (GKR not applied—epoch-level frequency does not require it)
This separation is intentional. CDK is a validated codebase receiving continuous updates from Polygon. Oraclizer’s innovations concentrate on OSS, where high-frequency state synchronization demands GKR’s computational efficiency.
Part 6: From Theory to Implementation
Implementation Challenges
For GKR’s theoretical excellence to translate into practical implementation, several challenges remain:
1. Circuit Depth and Security
GKR’s sumcheck security is affected by circuit depth. Circuits that are too shallow may be vulnerable to challenge prediction attacks in Fiat-Shamir transformations. Appropriate depths must be determined for the various operations in state oracles.
2. Non-uniform Circuit Handling
Real state synchronization includes diverse operations. Since GKR is optimized for repeated application of identical functions, methods for efficiently handling heterogeneous operations are needed.
3. Memory Requirements
GKR provers must maintain the entire circuit evaluation results in memory. Memory management strategies become important during large-scale batch processing.
Future Research Directions
This research established the foundation for state oracle proof optimization. In subsequent research:
- Incremental Proving: Additional optimization by proving only deltas of state changes
- Recursive Aggregation: Combining multiple GKR proofs into a single proof
- Heterogeneous Circuit Batching: Optimizing GKR circuit construction for mixed operation types (hashes, signatures, state transitions) in single batches
These directions will further improve the computational efficiency of state synchronization.
Conclusion
State oracles have fundamentally different proof requirements than data oracles. They must verify the correctness of continuous state flows, which was computationally infeasible due to intermediate commitment overhead in traditional SNARK systems.
The GKR protocol provides the computational foundation that makes state oracles possible. Through recursive application of sumcheck, it completely eliminates intermediate commitments, dramatically reducing proof generation computation by committing only to inputs and outputs. It is important to note that GKR provides computational efficiency, not zero-knowledge—privacy properties are added through the subsequent fflonk wrapping stage.
Oraclizer applies GKR to OSS for high-frequency state synchronization, with fflonk for proof generation and zkVerify for verification optimization. D-quencer consensus operates on BLS multisig, which is sufficient for its epoch-level frequency requirements. This three-stage framework achieves the computational feasibility of continuous state synchronization while maintaining compatibility with the CDK ecosystem.
State synchronization is no longer just a theoretical concept. The computational efficiency that GKR provides is the decisive factor transforming it into a feasible primitive.
Acknowledgments
We express special gratitude to Vitalik Buterin for his comprehensive GKR tutorial published in October 2025. His work illuminating the practical applications of this protocol—from Poseidon hash optimization to the broader implications for blockchain verification—provided crucial inspiration for identifying GKR as a key enabler of oracle state machine. The insight that intermediate commitment elimination could fundamentally change the computational feasibility of continuous state verification emerged directly from studying his exposition of the sumcheck recursive structure.
References
- Goldwasser, S., Kalai, Y.T., & Rothblum, G.N. (2015). Delegating Computation: Interactive Proofs for Muggles. Journal of the ACM, 62(4), 1-64. https://dl.acm.org/doi/10.1145/2699436
- Buterin, V. (2025). A GKR Tutorial. https://vitalik.eth.limo/general/2025/10/19/gkr.html
- Gabizon, A., & Williamson, Z.J. (2021). fflonk: a Fast-Fourier inspired verifier efficient version of PlonK. Cryptology ePrint Archive, Report 2021/1167. https://eprint.iacr.org/2021/1167.pdf
- Grassi, L., Khovratovich, D., Rechberger, C., Roy, A., & Schofnegger, M. (2021). Poseidon: A New Hash Function for Zero-Knowledge Proof Systems. USENIX Security Symposium. https://eprint.iacr.org/2019/458.pdf
- Thaler, J. (2022). Proofs, Arguments, and Zero-Knowledge. Foundations and Trends in Privacy and Security. https://people.cs.georgetown.edu/jthaler/ProofsArgsAndZK.pdf
- Horizen Labs. (2024). zkVerify: Modular Blockchain for ZK Proof Verification. https://zkverify.io/



