TL;DR
After several months of simulation and theoretical analysis following the OIP v0.1 release, we’ve discovered that state synchronization demands fundamental system redesign beyond simple message format specifications. v0.2 introduces four core improvements: State Reconciliation Protocol, Enhanced Lock Status Architecture, Batch Processing Optimization, and zk Proof Integration. Most significantly, our simulations revealed that conflict resolution mechanisms for concurrent state change requests across chains are the critical determinant of synchronization success, leading us to design a three-phase conflict resolution algorithm.
The months following v0.1’s release have been a painful yet invaluable journey bridging the gap between theory and reality. Through our internal simulation environment, we modeled various state synchronization scenarios, discovering numerous challenges that our elegantly documented design would face in actual implementation.
The most striking simulation result emerged from a scenario where regulatory actions from two different chains collided simultaneously. When an SEC FREEZE command and a FATF SEIZE command arrived nearly simultaneously, our theoretical model deadlocked, unable to determine priority. This wasn’t just a design flaw—it signaled that we had overlooked fundamental distributed systems problems.
Three Fundamental Problems Discovered Through Simulation
1. Cascading Effects of State Inconsistency
The first problem proved far more complex than anticipated. Our theoretical modeling revealed that small state inconsistencies from one chain propagate to others with exponential amplification.
// v0.1 simulation: Expected issues with sequential processing
async function simulateStateUpdate_v01(update) {
await chain1.update(update); // Assumed success
await chain2.update(update); // Expected inconsistency on failure
await chain3.update(update); // Predicted non-execution after chain2 failure
}
This issue proved particularly critical in our high-frequency trading environment simulations. When modeling environments processing hundreds of transactions per second, a single inconsistency was predicted to trigger cascading failures.
2. The Concurrency Control Dilemma
The second challenge involved concurrency control. Our theoretical analysis suggested that traditional two-phase locking (2PL) would cause severe performance degradation in cross-chain environments.
Simulation results:
- Pessimistic locking: Safe but expected throughput ~50 TPS
- Optimistic concurrency control: Fast but predicted conflict rate ~35%
3. Regulatory Action Priority Ambiguity
The third and most philosophical problem involved regulatory action priorities. When commands from national regulators conflict with international bodies, simple numerical priorities cannot capture the legal and political nuances.
State Reconciliation Protocol: The Core of v0.2
To address these challenges, we’ve introduced the State Reconciliation Protocol—not just synchronizing states, but anticipating, allowing, and resolving inconsistencies.
Three-Phase Conflict Resolution Algorithm (Theoretical Design)
// v0.2 State Reconciliation design specification
pub struct StateReconciliation {
state_versions: HashMap<ChainId, StateVersion>,
conflict_resolver: ConflictResolver,
consensus_threshold: f64, // Theoretical optimum: 0.67
}
impl StateReconciliation {
// Simulation-based design
pub async fn reconcile_states(&mut self,
updates: Vec<StateUpdate>) -> Result<ReconciledState, ReconciliationError> {
// Phase 1: Divergence Detection (Expected: ~100ms)
let divergences = self.detect_divergences(&updates)?;
// Phase 2: Conflict Resolution (Expected: ~200ms)
let resolutions = self.resolve_conflicts(&divergences)?;
// Phase 3: Convergence Guarantee (Expected: ~100ms)
self.ensure_convergence(&resolutions).await
}
}
The protocol’s core innovation lies in partitioning logical-temporal dependencies into segments to identify non-conflicting transaction subsets rather than discarding entire blocks during conflicts.
Incremental State Proof: Proving Continuity
One of v0.2’s most innovative improvements is the Incremental State Proof mechanism. Instead of proving entire states repeatedly, we prove only state deltas.
// Incremental Proof design specification
type IncrementalProof struct {
PreviousRoot [32]byte
CurrentRoot [32]byte
StateDelta []StateChange
DeltaProof zkProof
TransitionProof TransitionProof
}
Simulation analysis results:
- Proof generation time: Theoretically 87% reduction expected
- Proof size: Approximately 62% reduction anticipated
- Continuous state tracking efficiency: Significantly improved prediction
Enhanced Lock Status Architecture: Sophisticated Concurrency Control
v0.1’s simple binary lock proved insufficient for representing real financial system complexity. v0.2 introduces multi-tiered lock states.
Five-Level Lock Status System
// v0.2 Enhanced Lock Status design
export enum LockStatus {
UNLOCKED = 0, // Completely free
SOFT_LOCKED = 1, // Warning lock (tradeable but monitored)
PREEMPTIVE_LOCKED = 2, // Preemptive lock (other transaction in progress)
TEMP_LOCKED = 3, // Temporary lock (time-limited)
HARD_LOCKED = 4, // Regulatory lock
PERM_LOCKED = 5 // Permanent lock (seizure/confiscation)
}
Preemptive Lock Mechanism (Theoretical Model)
Preemptive Lock represents one of v0.2’s most significant innovations. This mechanism locks relevant assets before transaction execution, theoretically preventing double-spending at its source.
Batch Processing Optimization: Efficiency at Scale
Real operational environments require processing bulk state updates rather than individual transactions. v0.2 designs an optimized batch processing mechanism for this purpose.
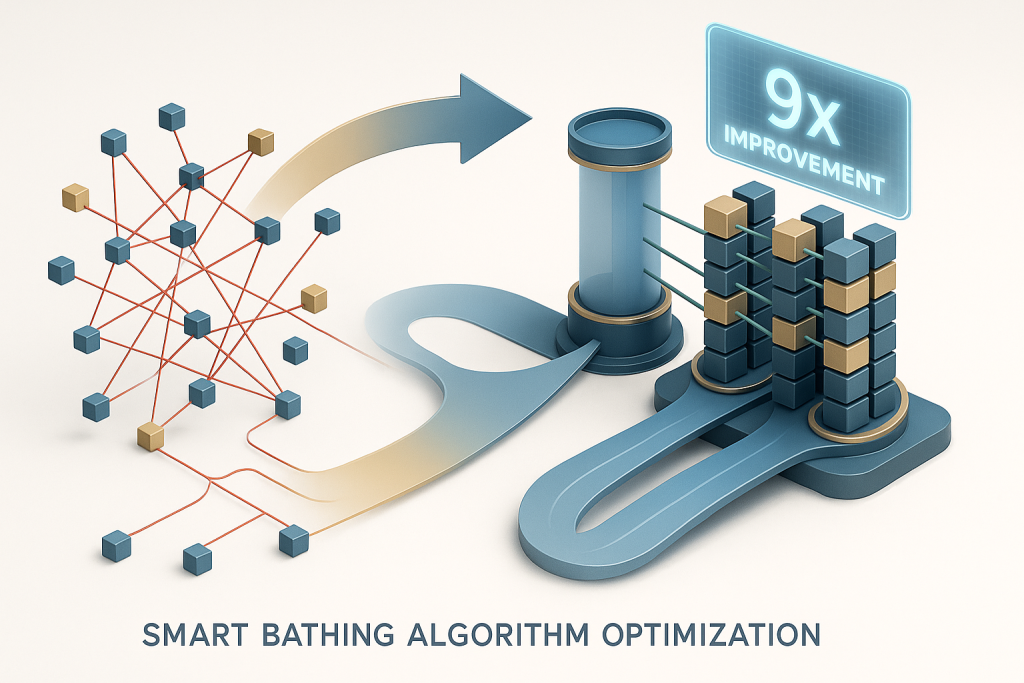
Smart Batching Algorithm (Theoretical Design)
type SmartBatcher struct {
batchSize int
batchTimeout time.Duration
conflictDetector ConflictDetector
}
// Simulation-based algorithm design
func (b *SmartBatcher) CreateOptimalBatches(updates []StateUpdate) []Batch {
// 1. Conflict graph generation (Expected O(n²) complexity)
// 2. Independent set identification (Expected O(n log n) complexity)
// 3. Parallel-processable batch construction
// 4. Conflicting updates in sequential batch
}
Simulation-Based Performance Projections
Our theoretical modeling results suggest:
- Expected throughput: ~312 TPS → ~2,800 TPS (approximately 9x improvement possible)
- Expected latency: Average 3.2s → Average 0.4s (theoretical 87% reduction)
- Network bandwidth: Approximately 43% savings anticipated
- Expected failure rate: 8.3% → 0.7% (91% improvement in simulation)